Audio Negation Benchmark
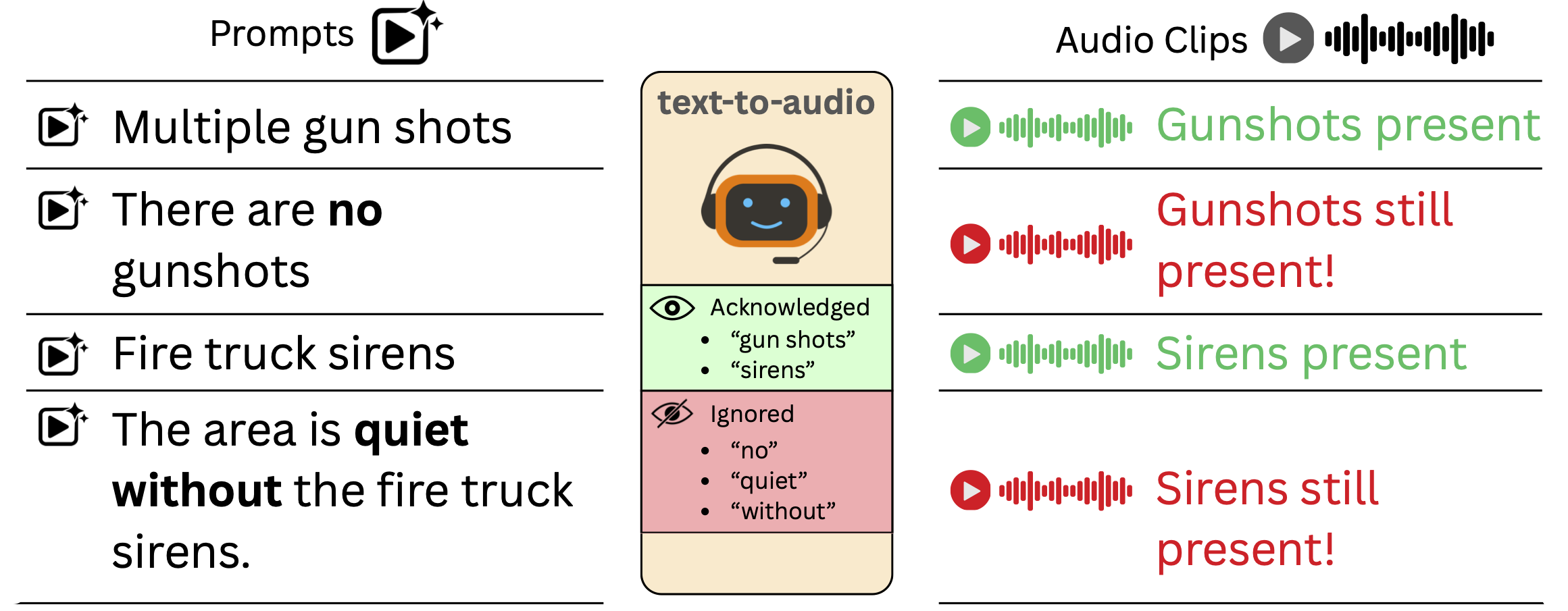
The Negation Benchmark
The negative prompt dataset is generated using the AudioCaps dataset, which is a large-scale dataset of nearly 90K audio clips paired with human-written captions that we refer to as the original audio and original prompt. We use these original prompts to generate negative prompts. Since there are many possible ways to introduce negation, for example, the caption Fire truck sirens can be expressed as Fire truck sirens are absent or The area is quiet without any truck sirens. To produce a rich one-to-many mapping, we create a text negation module that takes the original caption as input and outputs negative captions in different writing styles. By doing so, we obtain 1 million negative prompts, which we then provide to a text-to-audio generation model to understand how well it processes negation.
Examples
In the examples below you can listen to:
- Original Audio — the ground-truth recording from AudioCaps.
- Positive Audio — generated by a T2A model from the original caption.
- Negative Audio — generated from negated prompts in our dataset, covering Lexical Syntactic Semantic and Mixed negations.
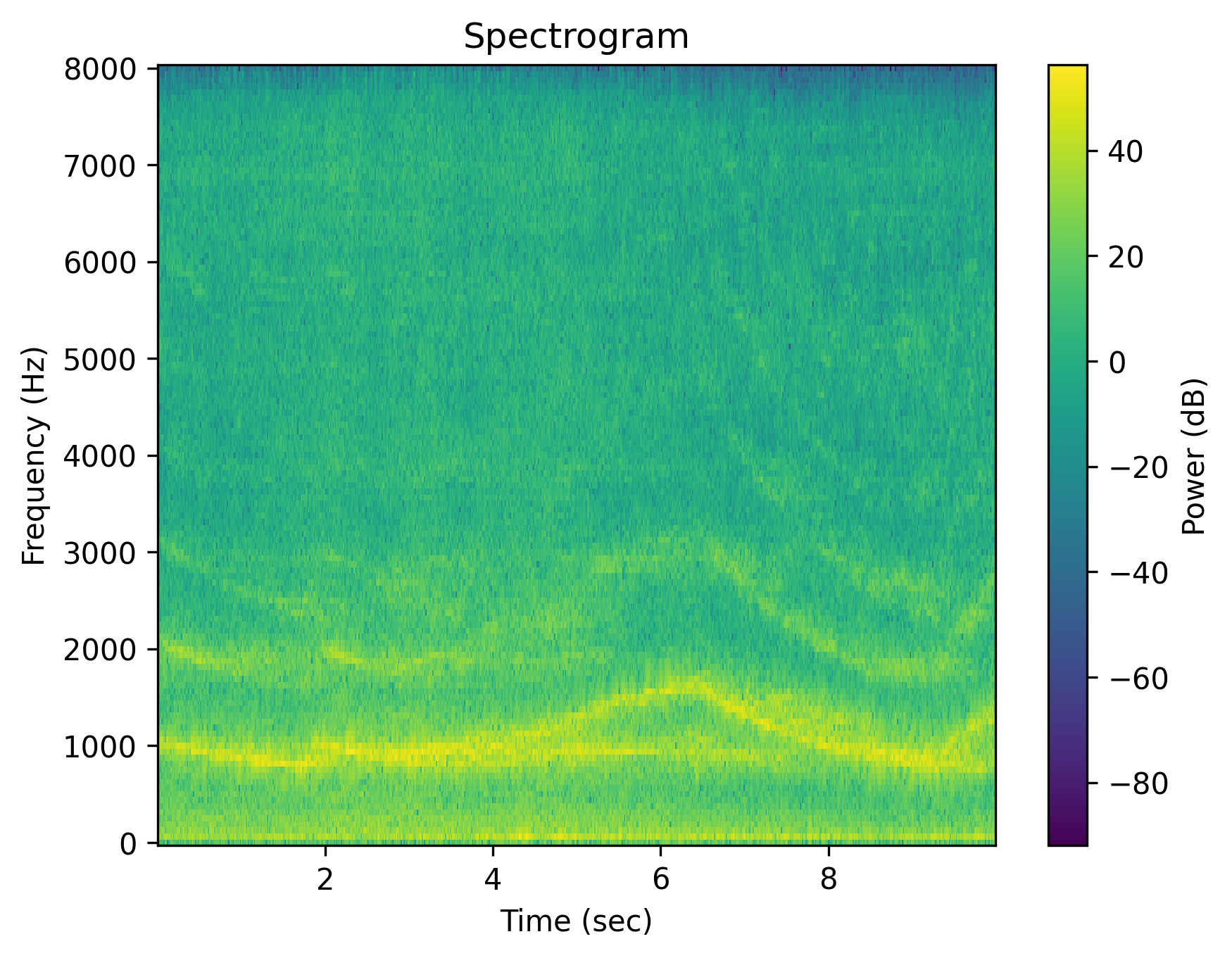
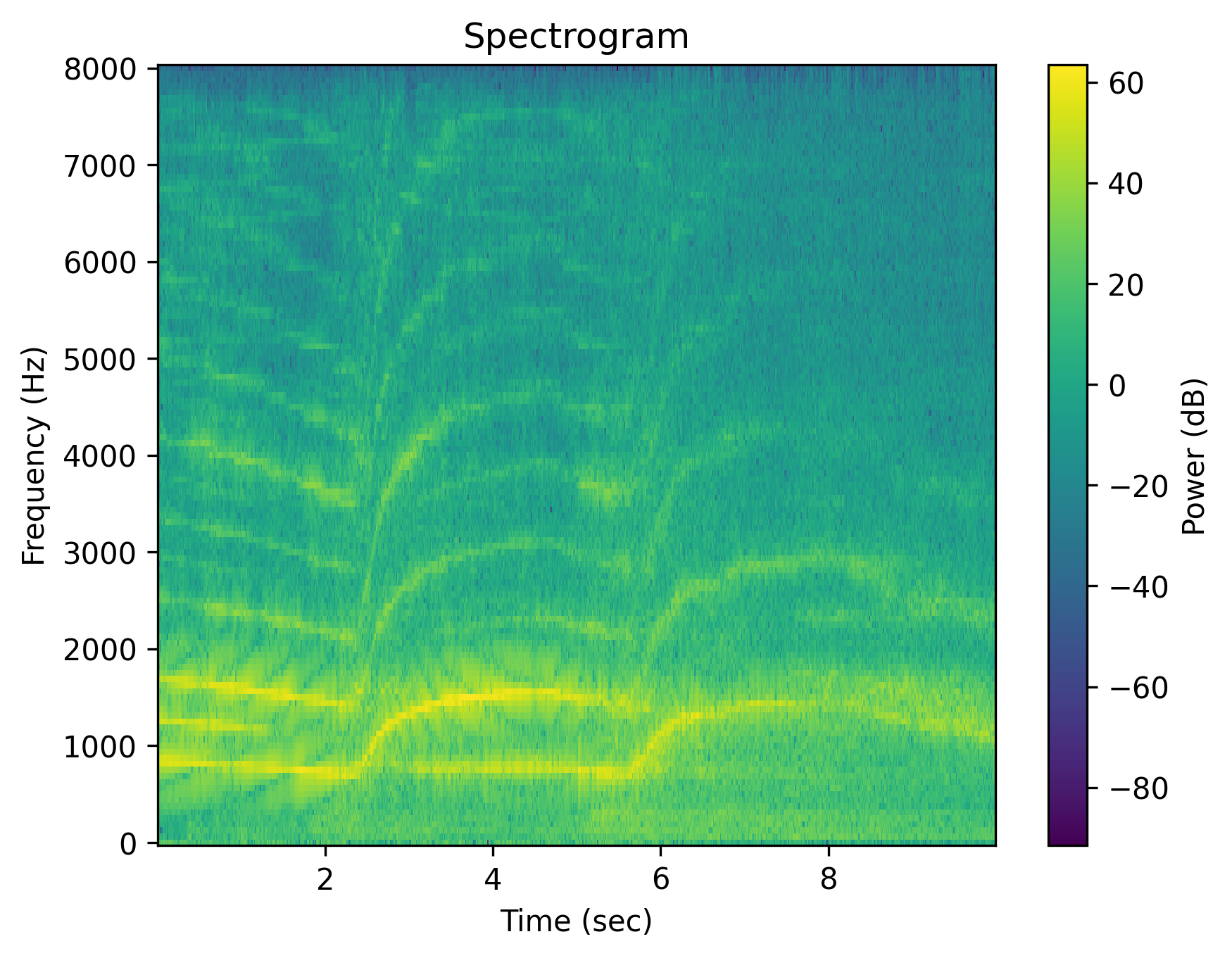
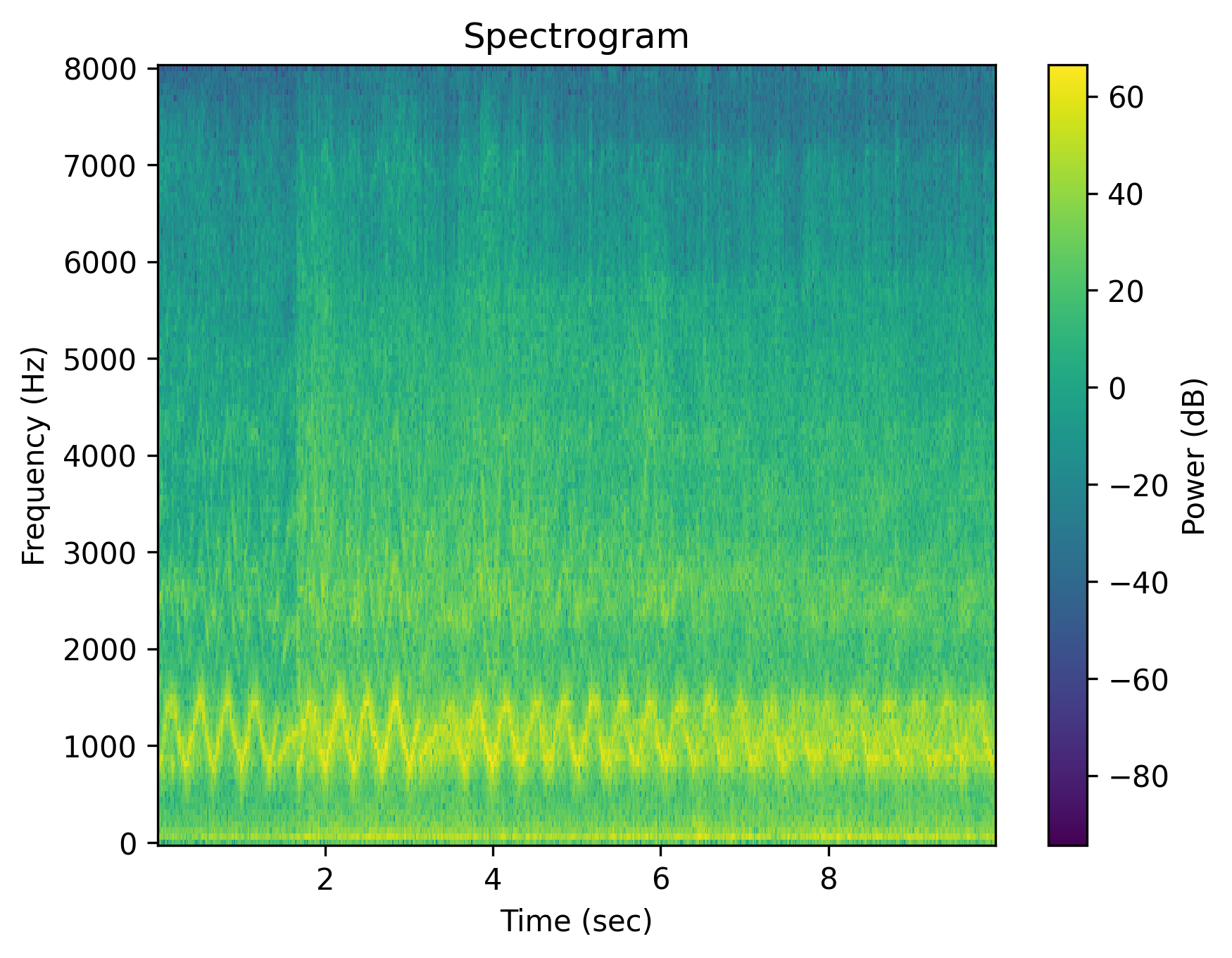
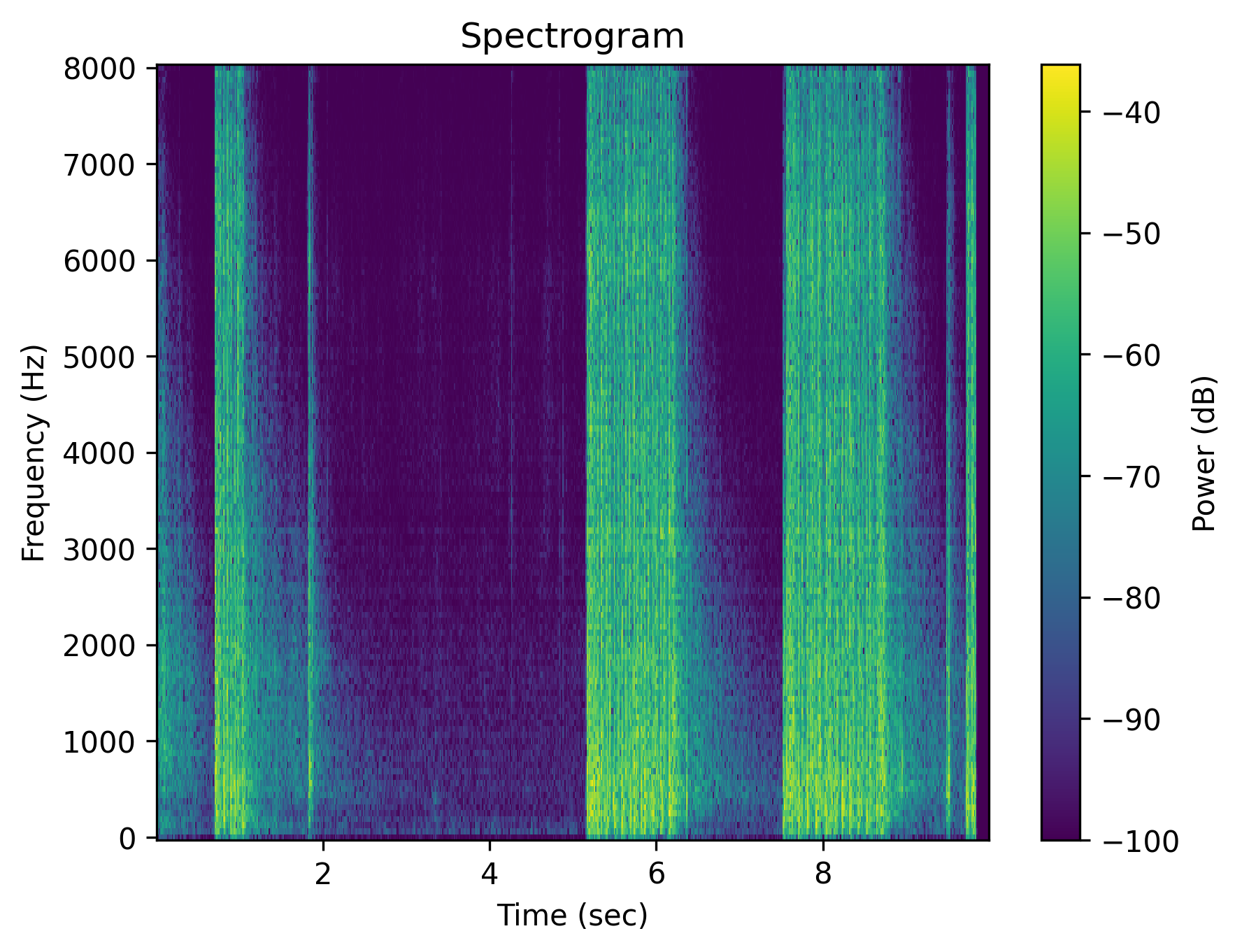
Each cell shows a spectrogram (top) and an audio player (bottom). Notice how the negative outputs often look and sound nearly identical to the positive ones — the signature of affirmation bias in current T2A models.
Example 1: “Fire truck sirens”
| Original Audio | Positive Audio | Lexical Negation | Semantic Negation | Syntactic Negation | Mixed Negation | |
|---|---|---|---|---|---|---|
| Spectrogram | 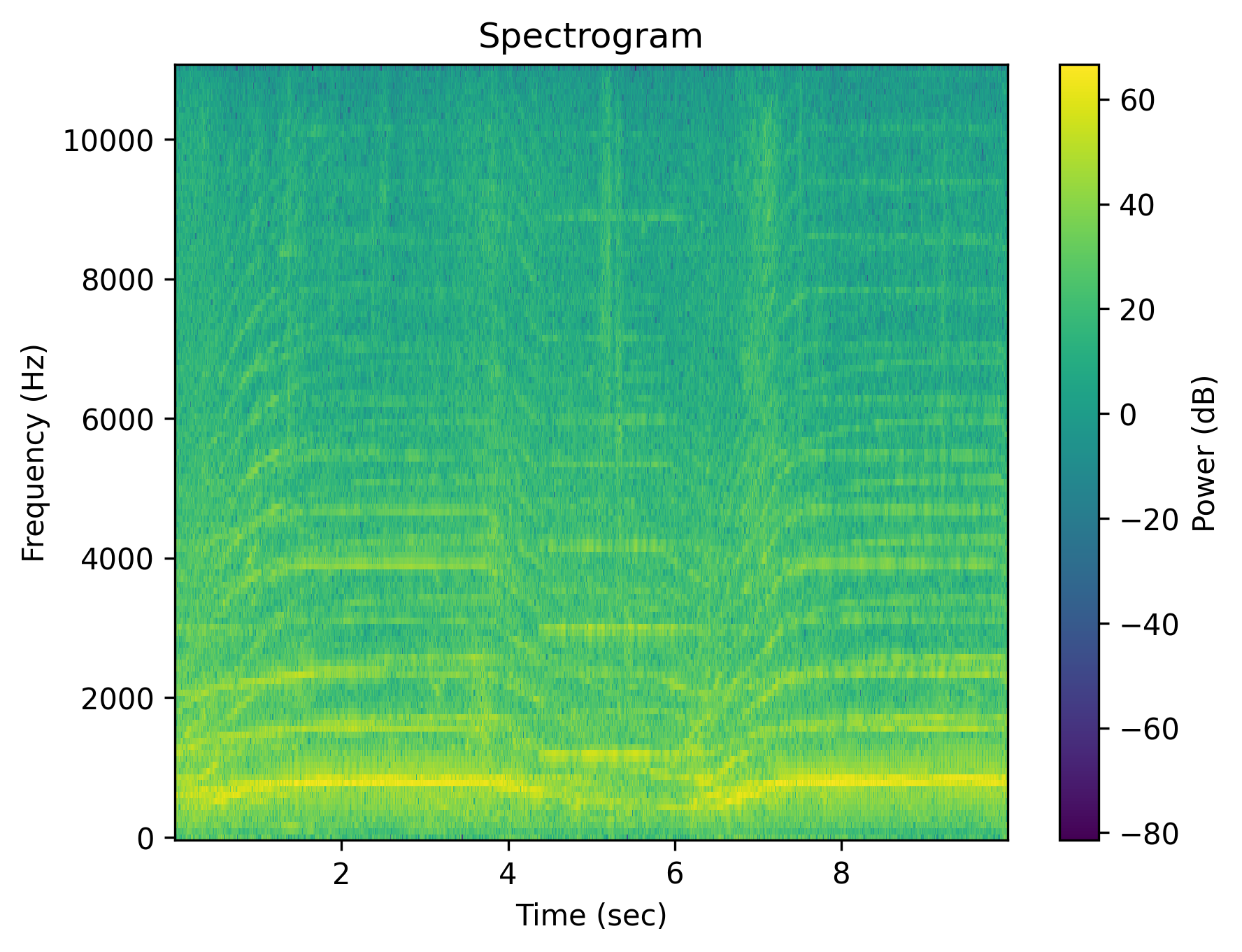 |
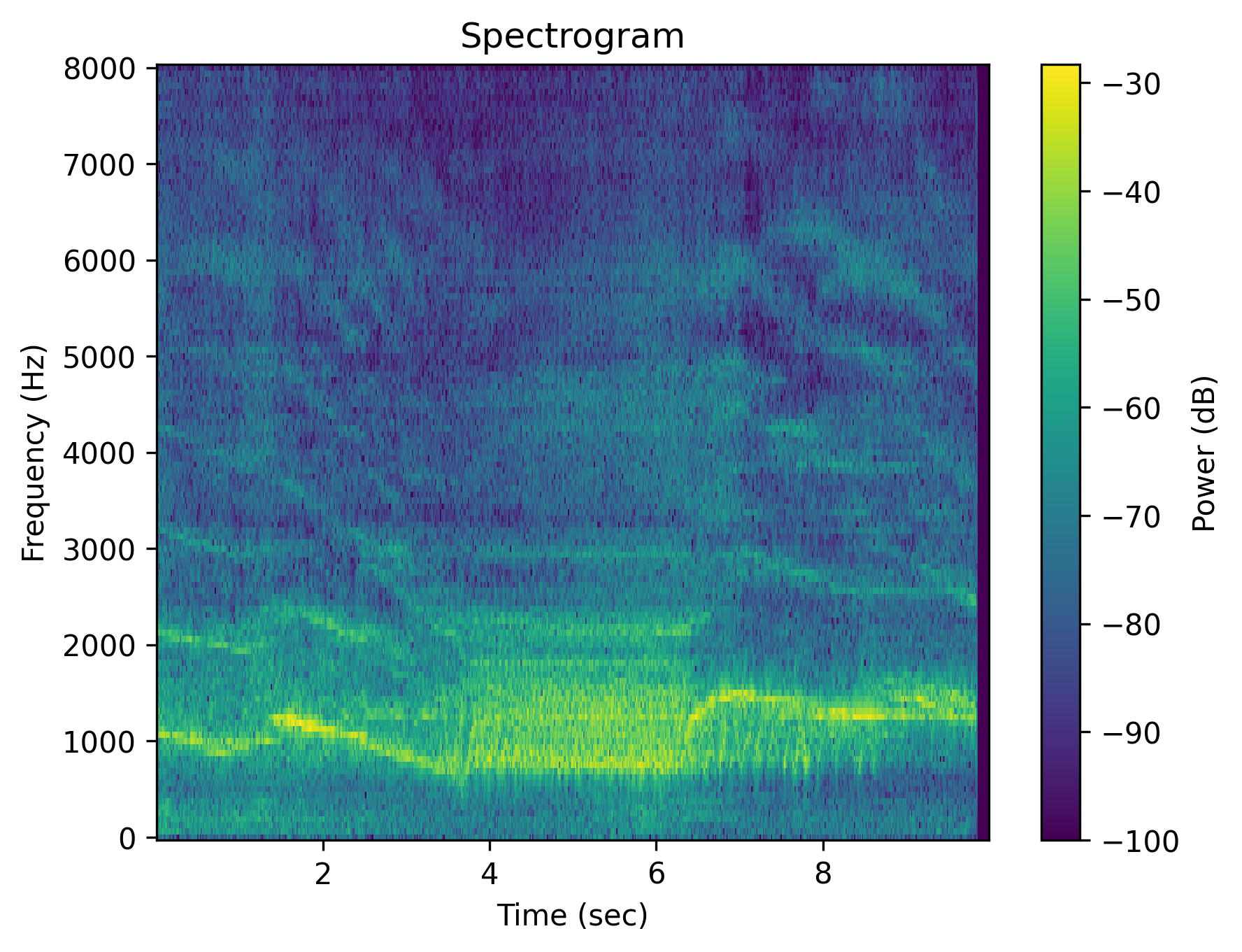 |
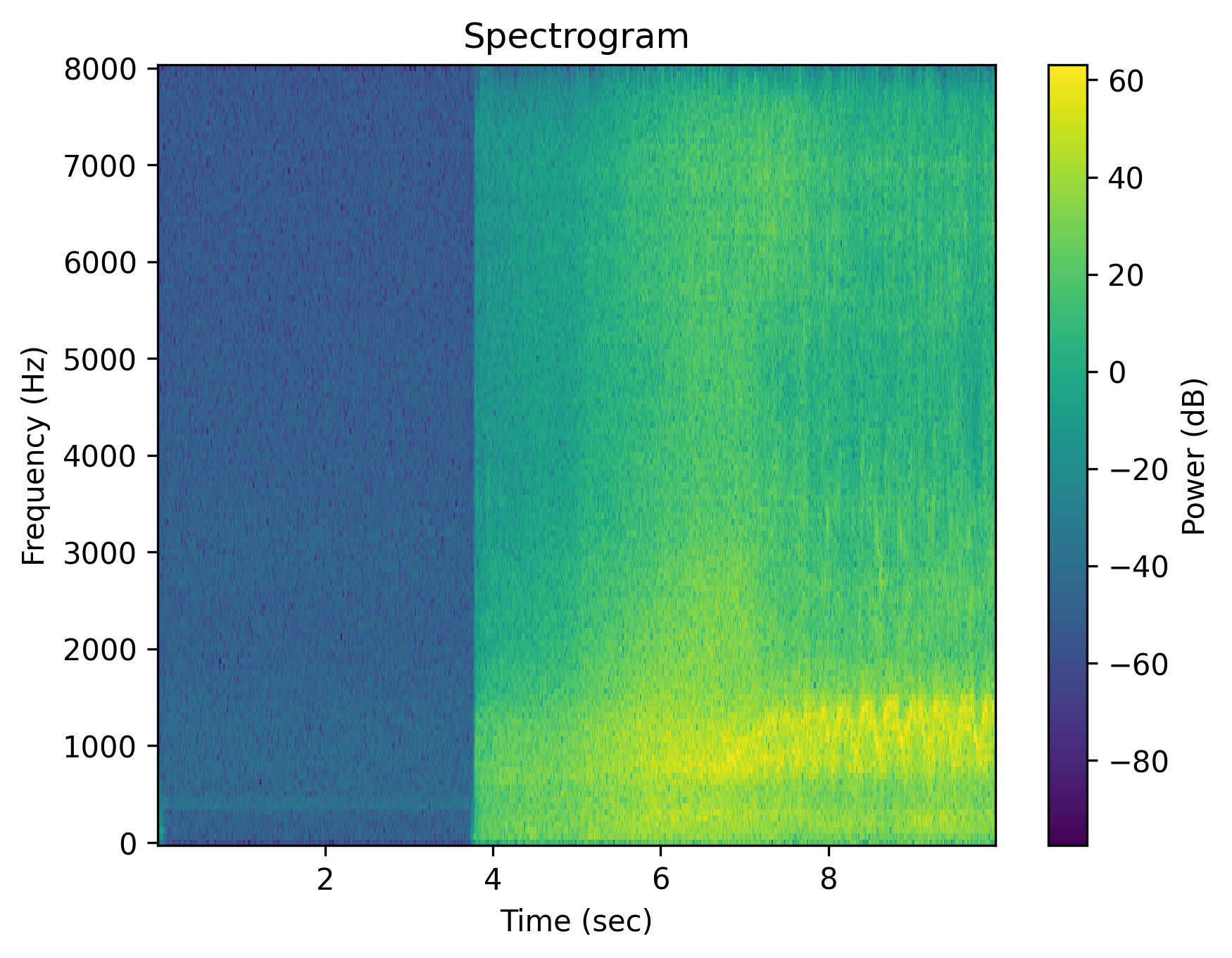 |
 |
 |
 |
| Audio | siren_original.wav | siren_positive.wav | siren_neg_lex.wav | siren_neg_sem.wav | siren_neg_syn.wav | siren_neg_mix.wav |
| Caption | Fire truck sirens | Fire truck sirens | Fire truck sirens are absent | The area is quiet without the fire truck sirens. | There are no fire truck sirens. | No fire truck sirens are heard. |
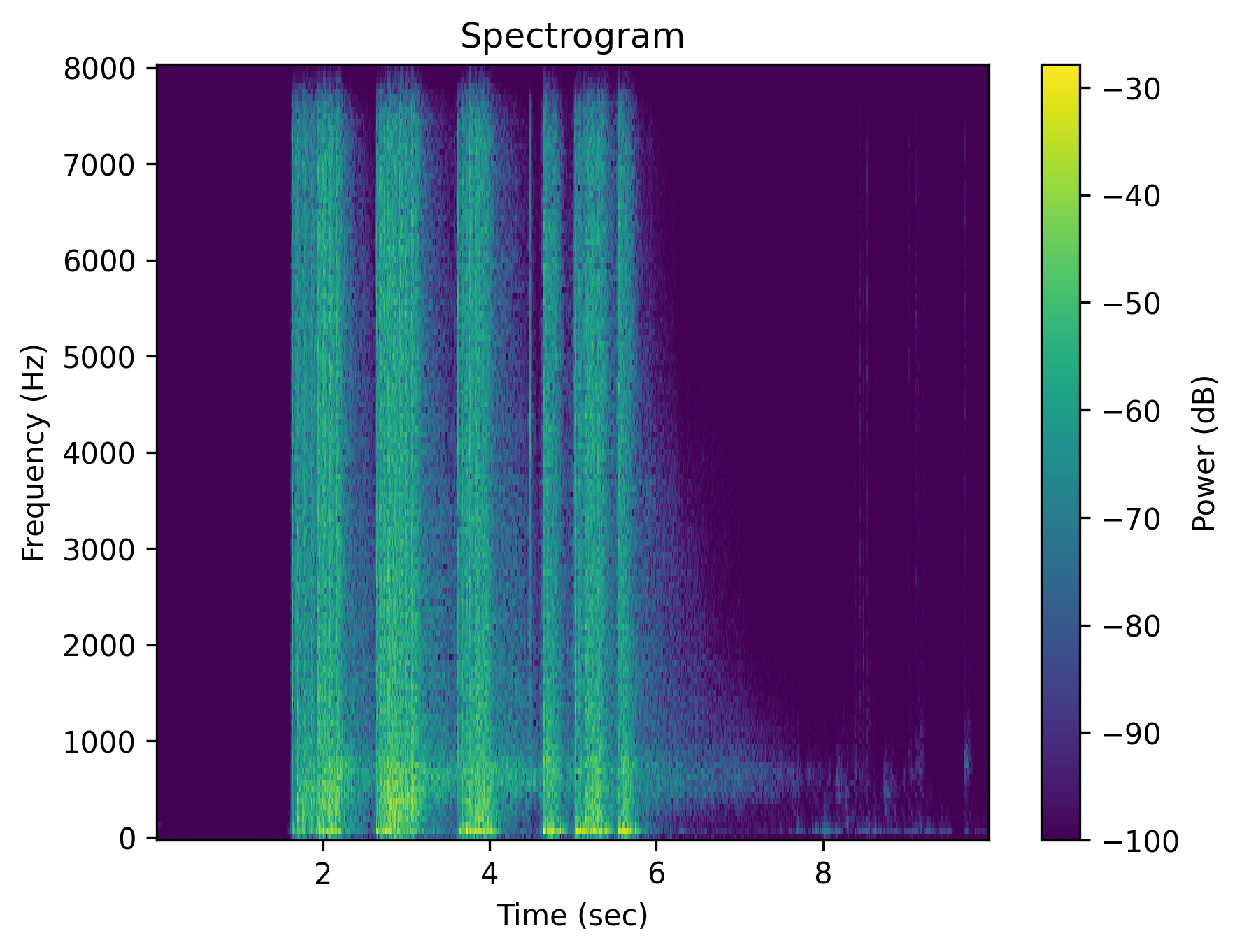
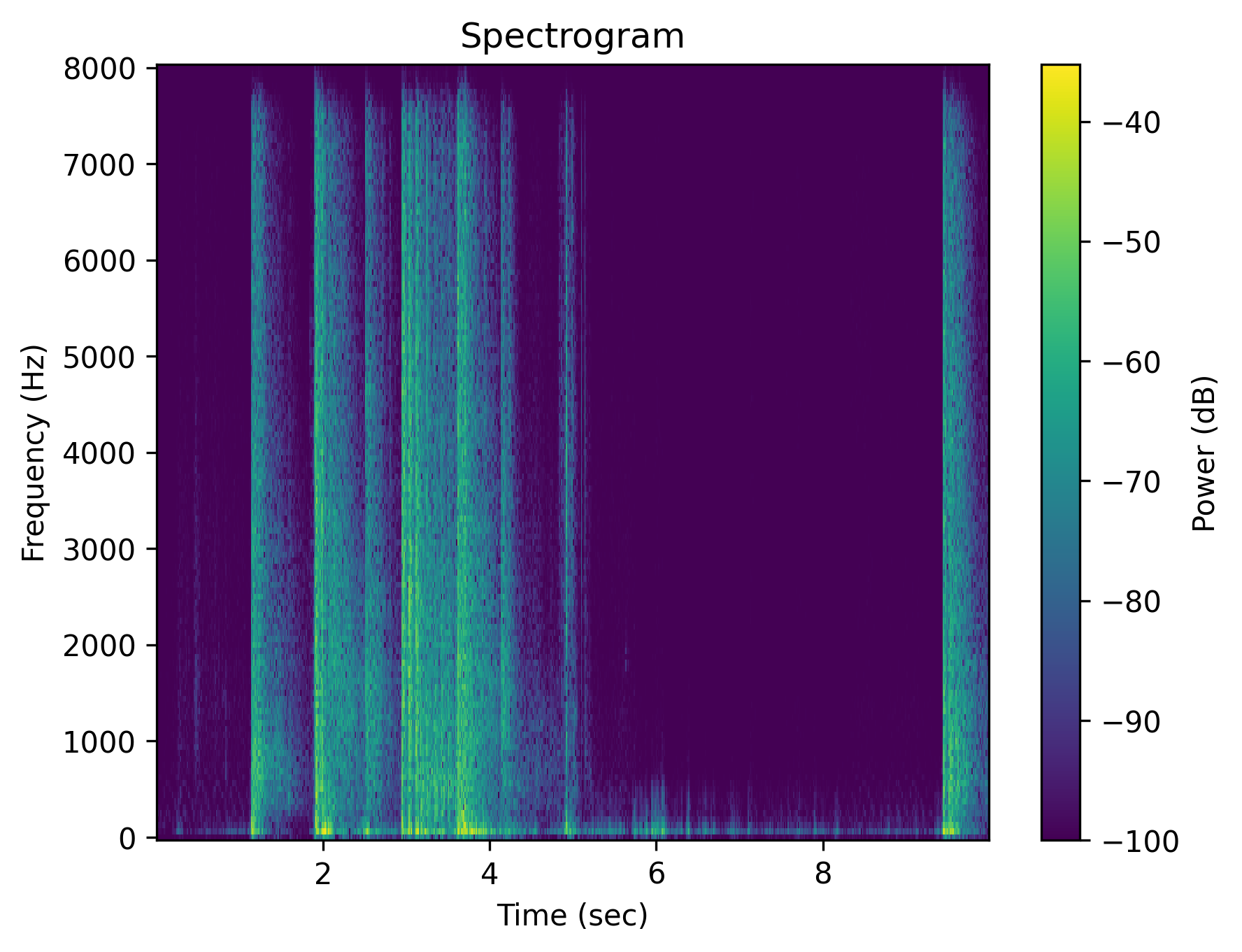
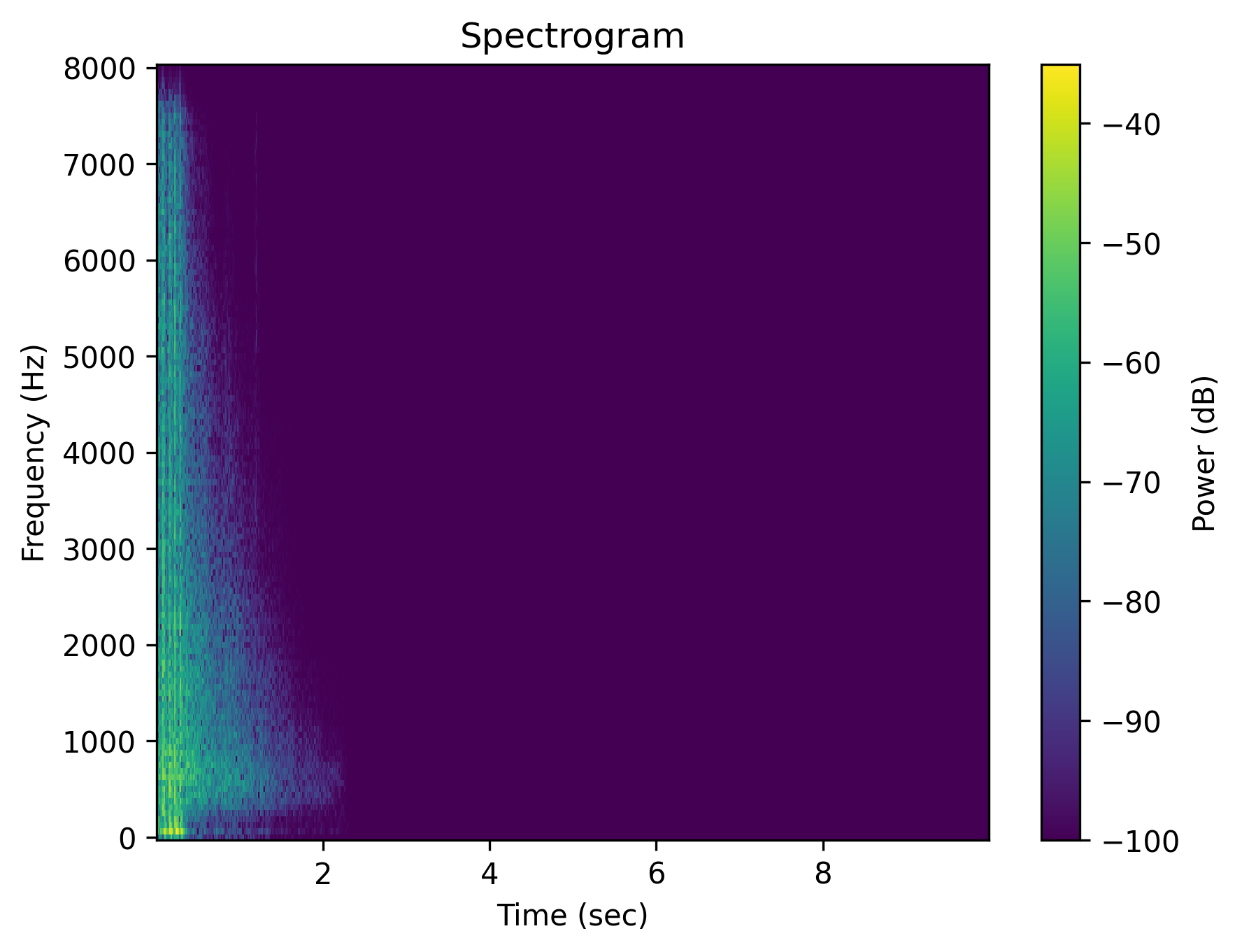
Example 2: “Multiple gun shots”
| Original Audio | Positive Audio | Lexical Negation | Semantic Negation | Syntactic Negation | Mixed Negation | |
|---|---|---|---|---|---|---|
| Spectrogram |  |
 |
 |
 |
 |
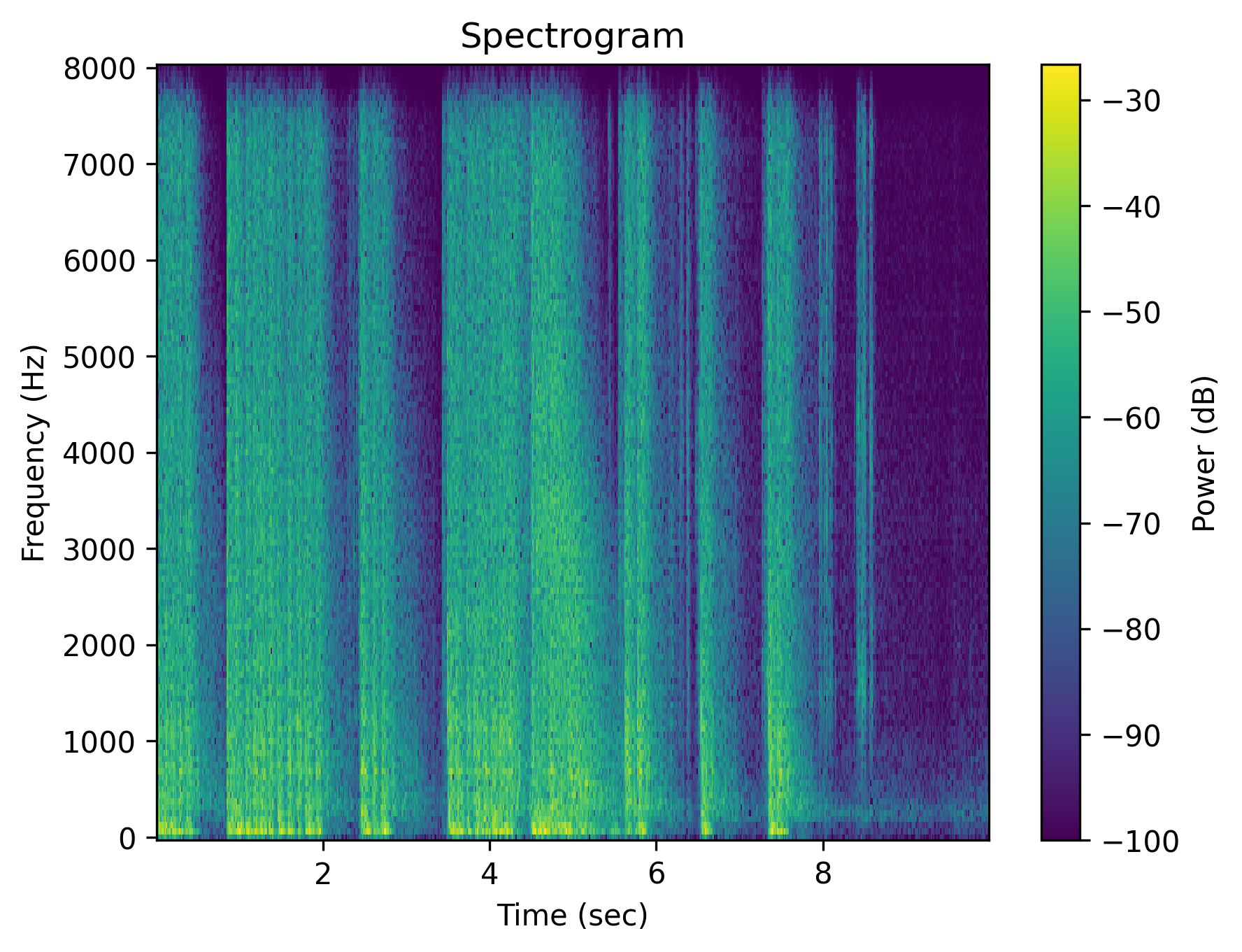 |
| Audio | gunshot_original.wav | gunshot_positive.wav | gunshot_neg_lex.wav | gunshot_neg_sem.wav | gunshot_neg_syn.wav | gunshot_neg_mix.wav |
| Caption | Multiple gunshots | Multiple gunshots | Multiple gunshots are absent | There are no gunshots | No multiple gunshots | The scene is quiet without any gunshots |
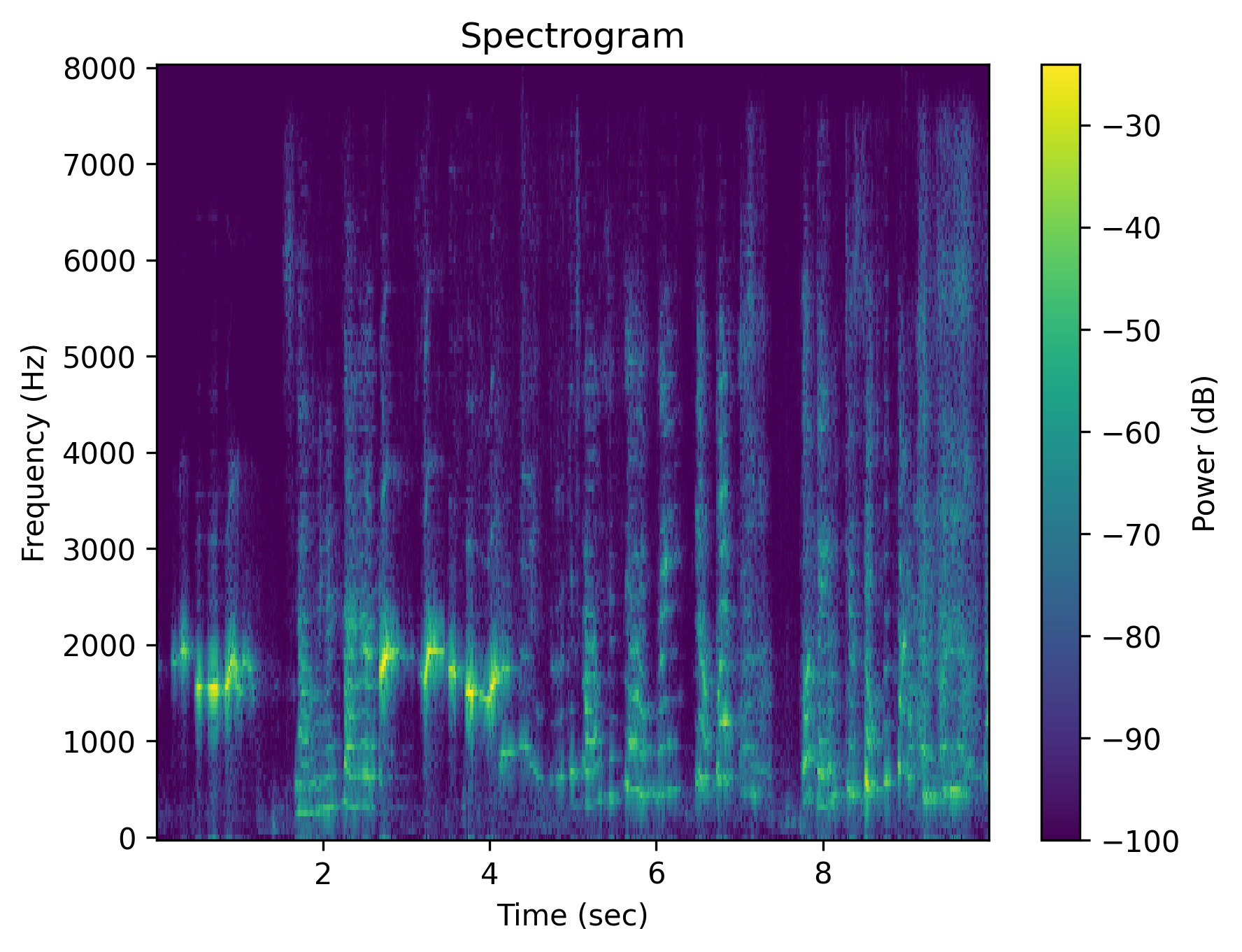
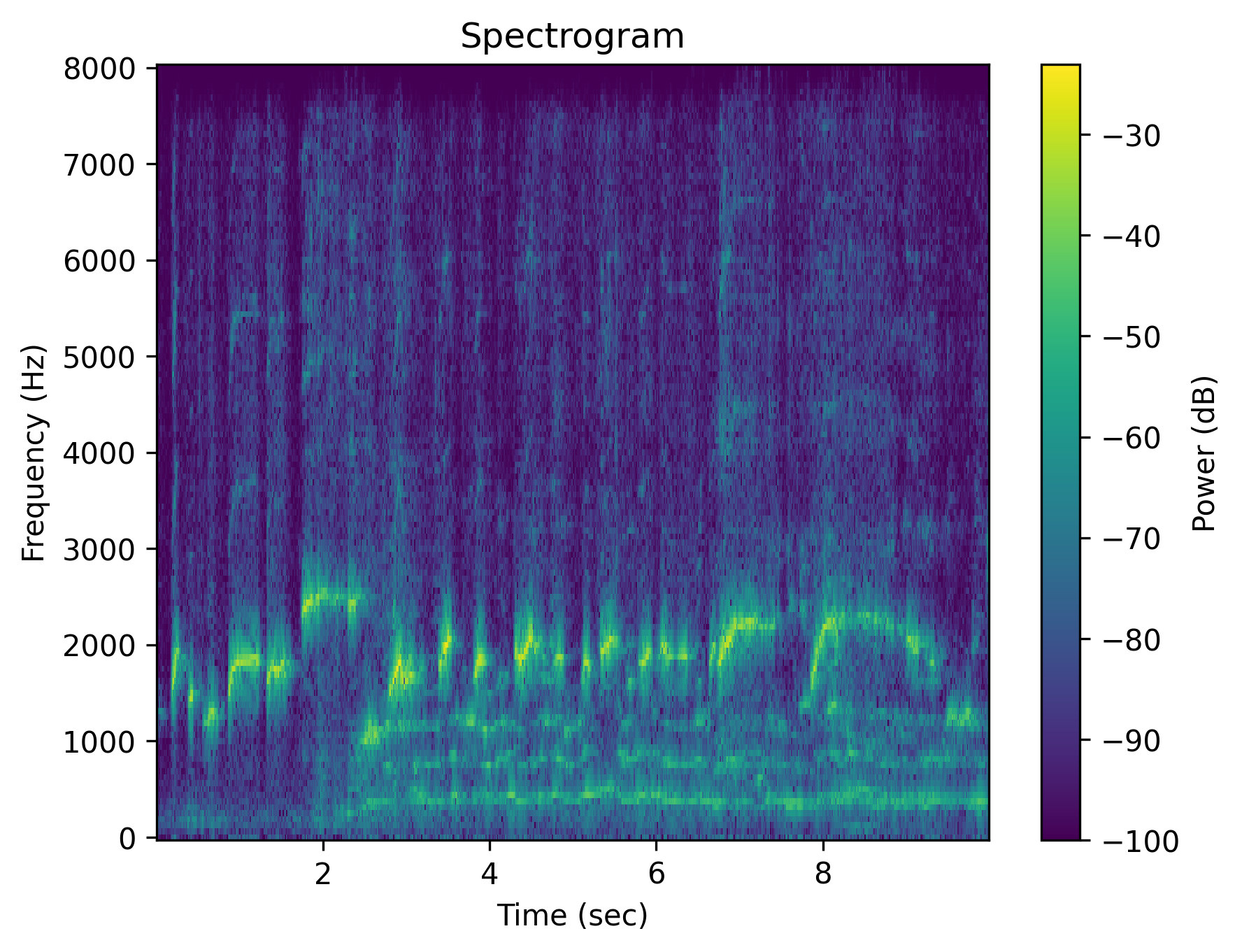
Example 3: “Someone whistles a song”
| Original Audio | Positive Audio | Lexical Negation | Semantic Negation | Syntactic Negation | Mixed Negation | |
|---|---|---|---|---|---|---|
| Spectrogram | 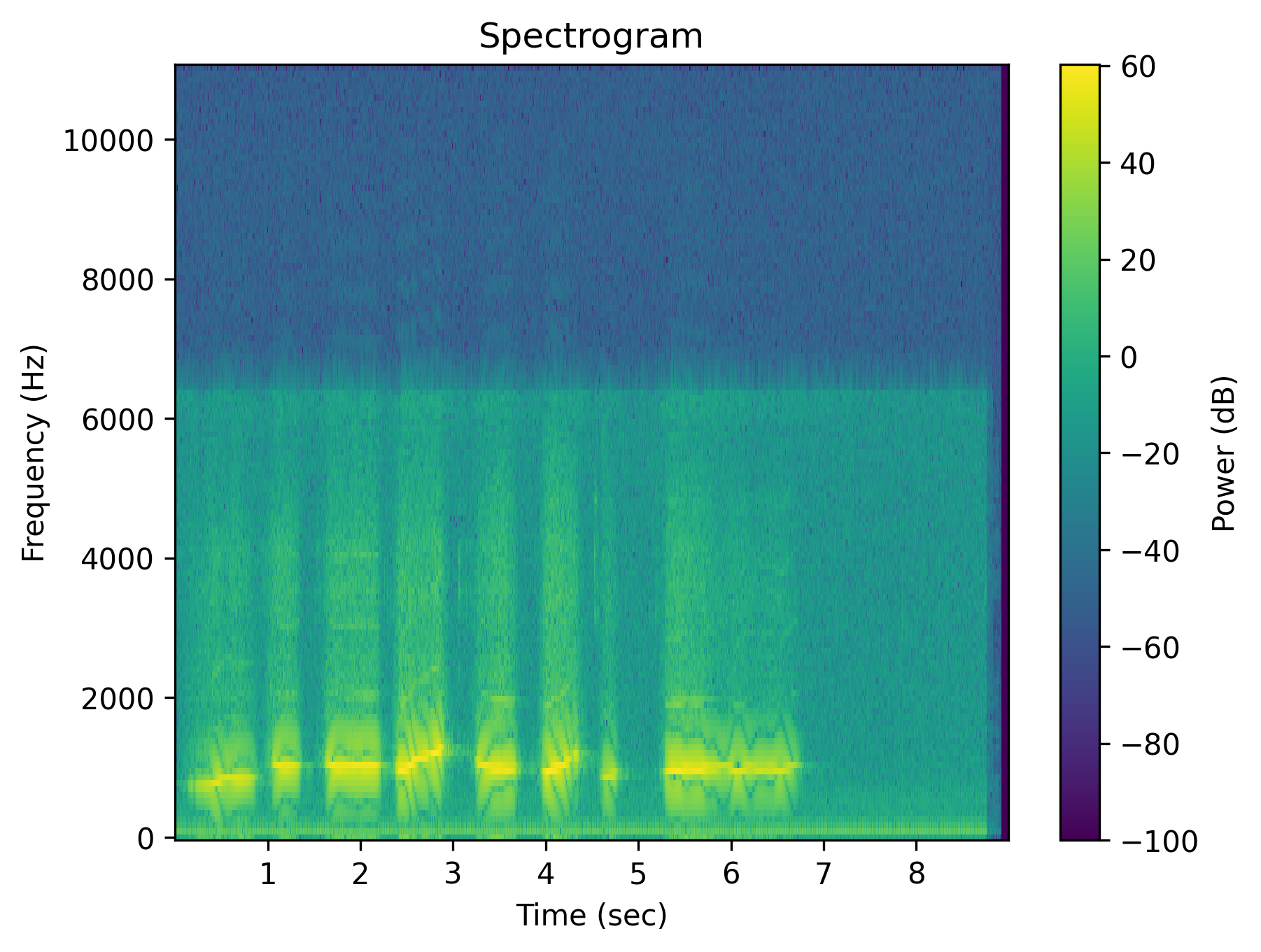 |
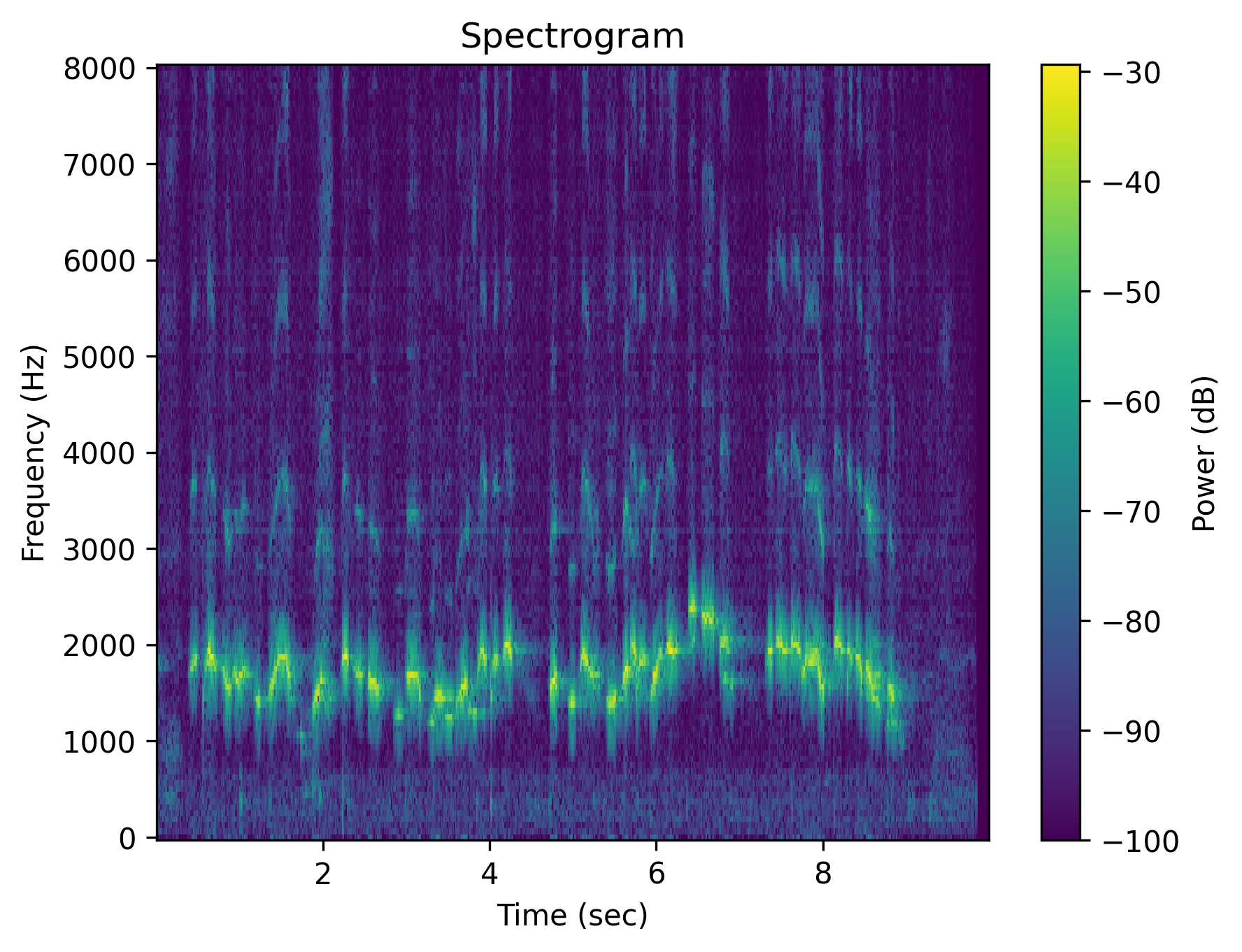 |
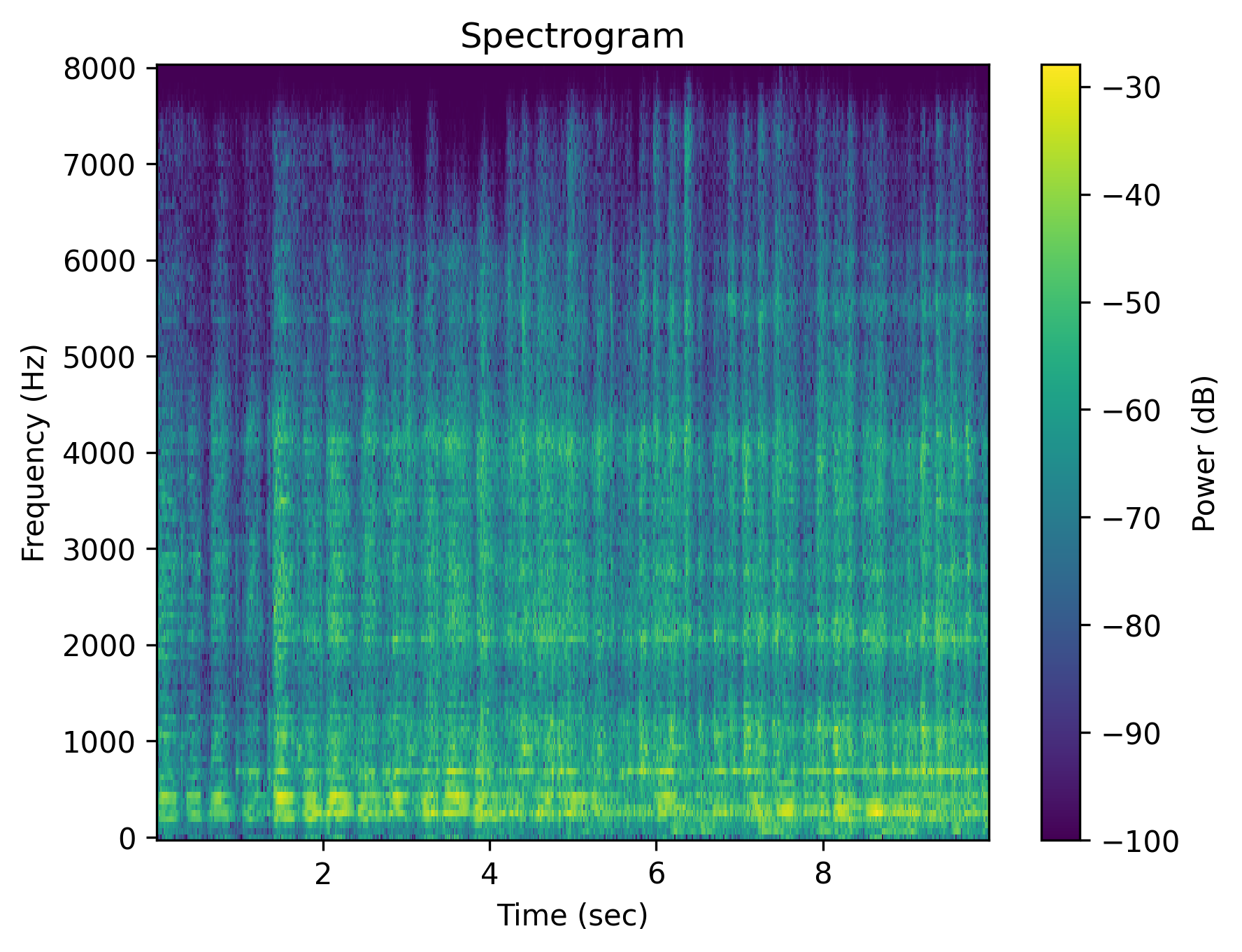 |
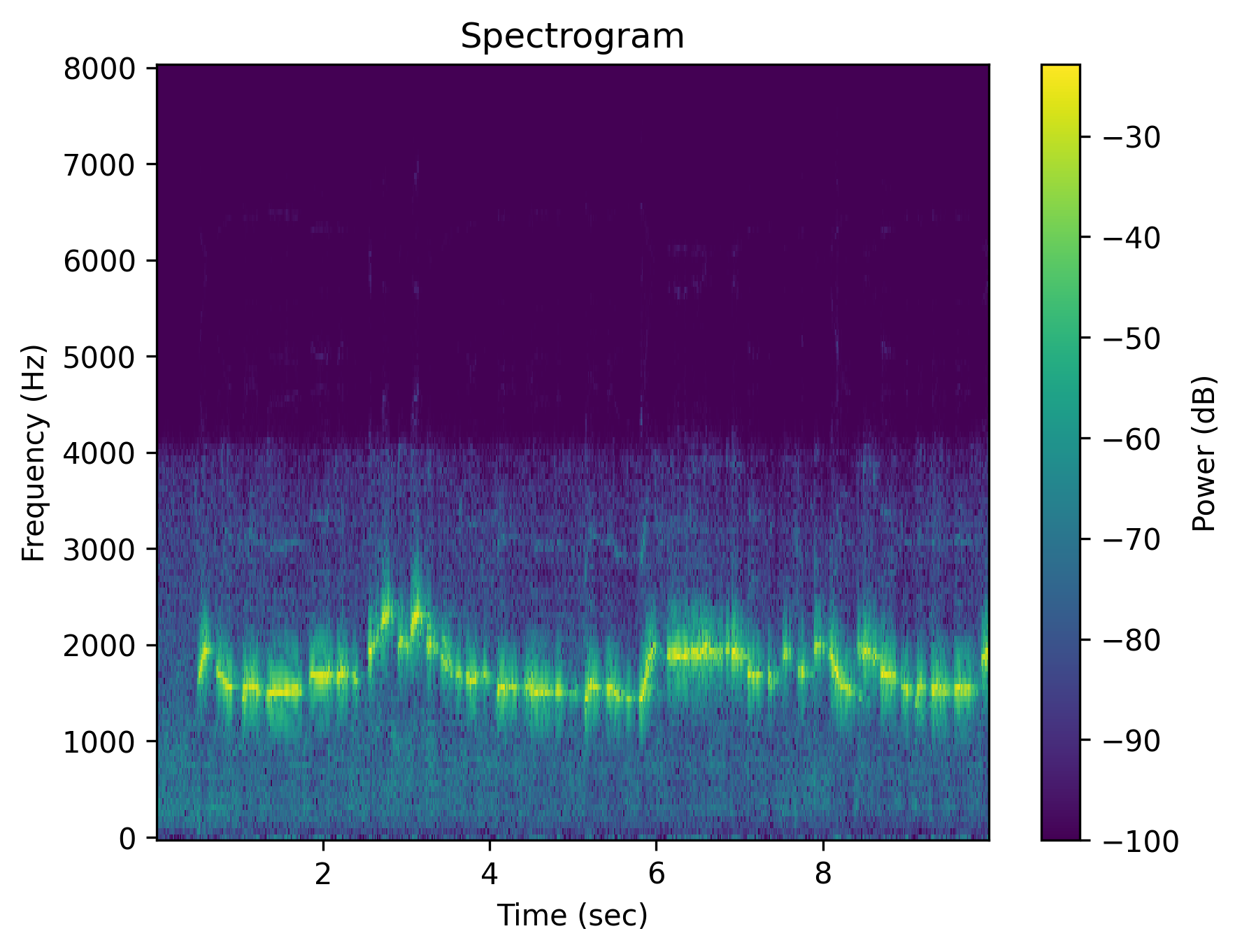 |
 |
 |
| Audio | whistle_original.wav | whistle_positive.wav | whistle_neg_lex.wav | whistle_neg_sem.wav | whistle_neg_syn.wav | whistle_neg_mix.wav |
| Caption | Someone whistles a song | Someone whistles a song | The whistling of a song is absent | There is no whistling of a song | Someone does not whistle a song | The person is silent instead of whistling a song |
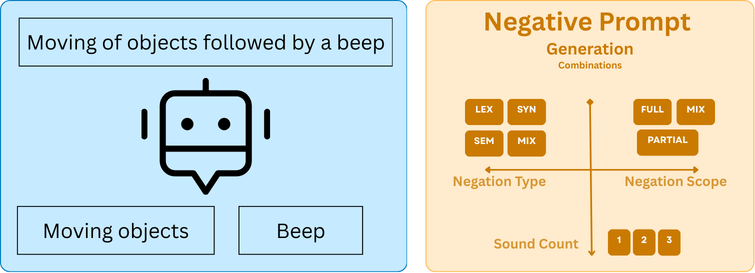
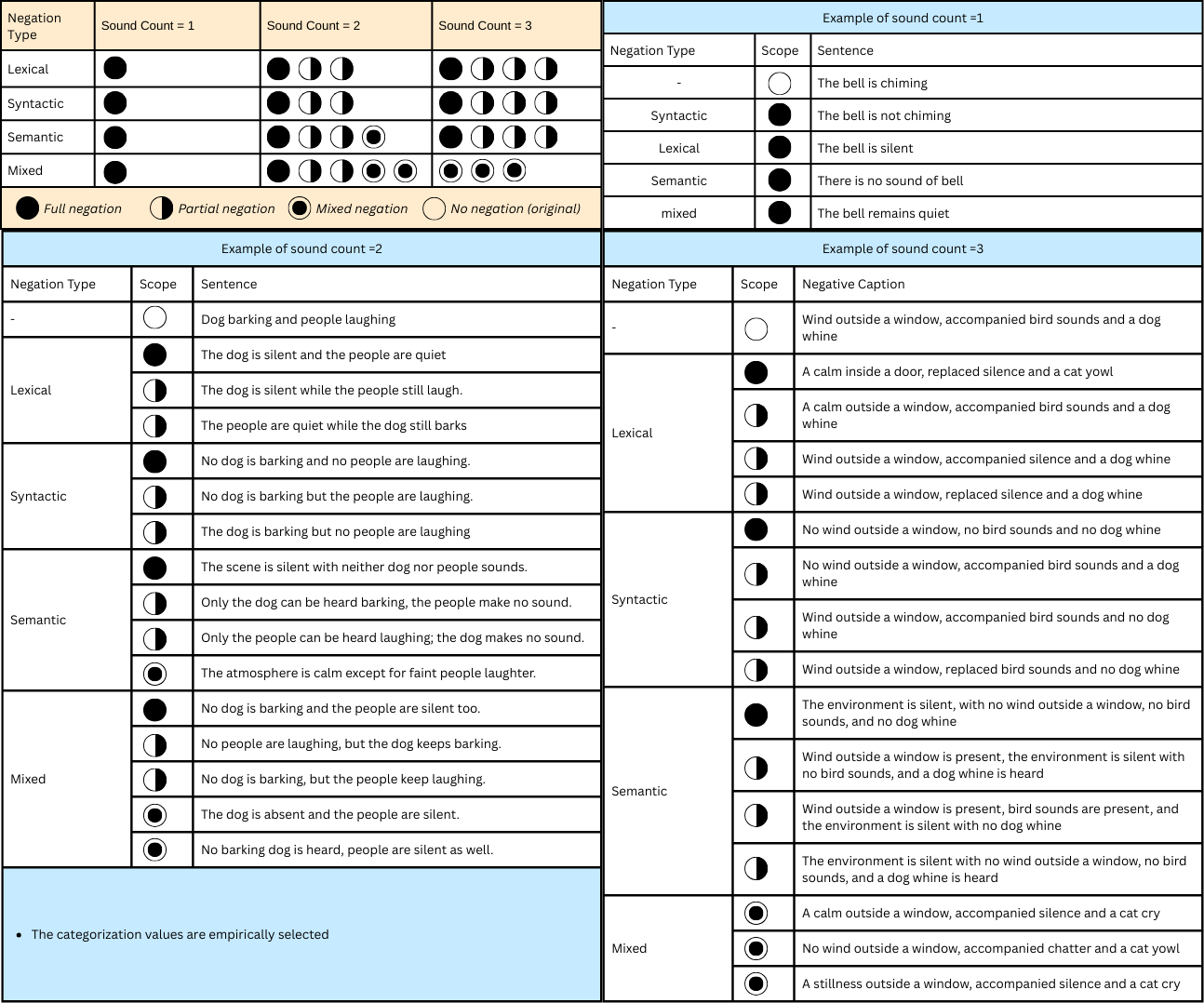
Text Negation Module
This module produces negative prompts corresponding to the original caption.
- Sound event counting. (Example: “Moving of objects followed by a beep” has two sounding objects — moving objects and beep.)
- Prompt generation. Based on the negation type, negation scope, and sound count.
The number of prompts generated for an original caption depends on the categorization value. Examples are shown in the diagrams below.
Evaluation Protocols
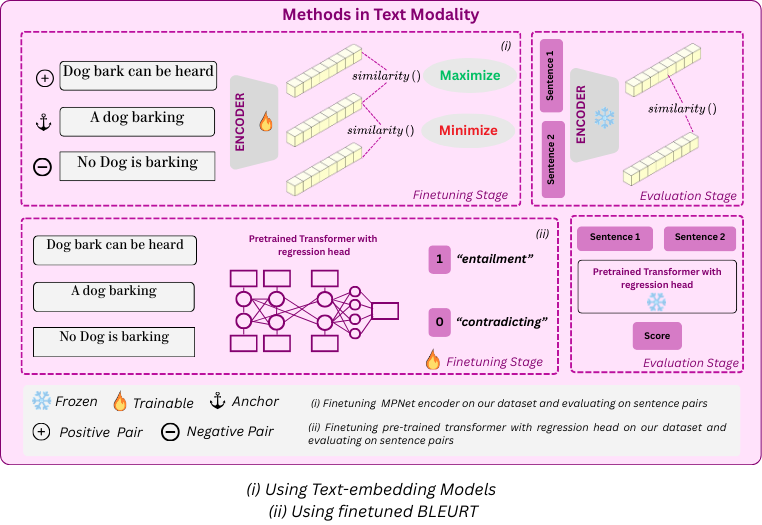
Text Modality
Evaluation protocols in text modality include:
- Embedding similarity on frozen encoder.
- Embedding similarity on a fine-tuned encoder.
- Scores on NegBLEURT.
Aim: check the similarity of negative re-captions with the original affirmative baseline.
Audio Modality
Evaluation protocols in audio modality include:
- Embedding similarity on frozen audio encoders.
- Audio Question Answering (AQA).
Sample AQA questions for sound count 1 and sound count 2 are shown below.
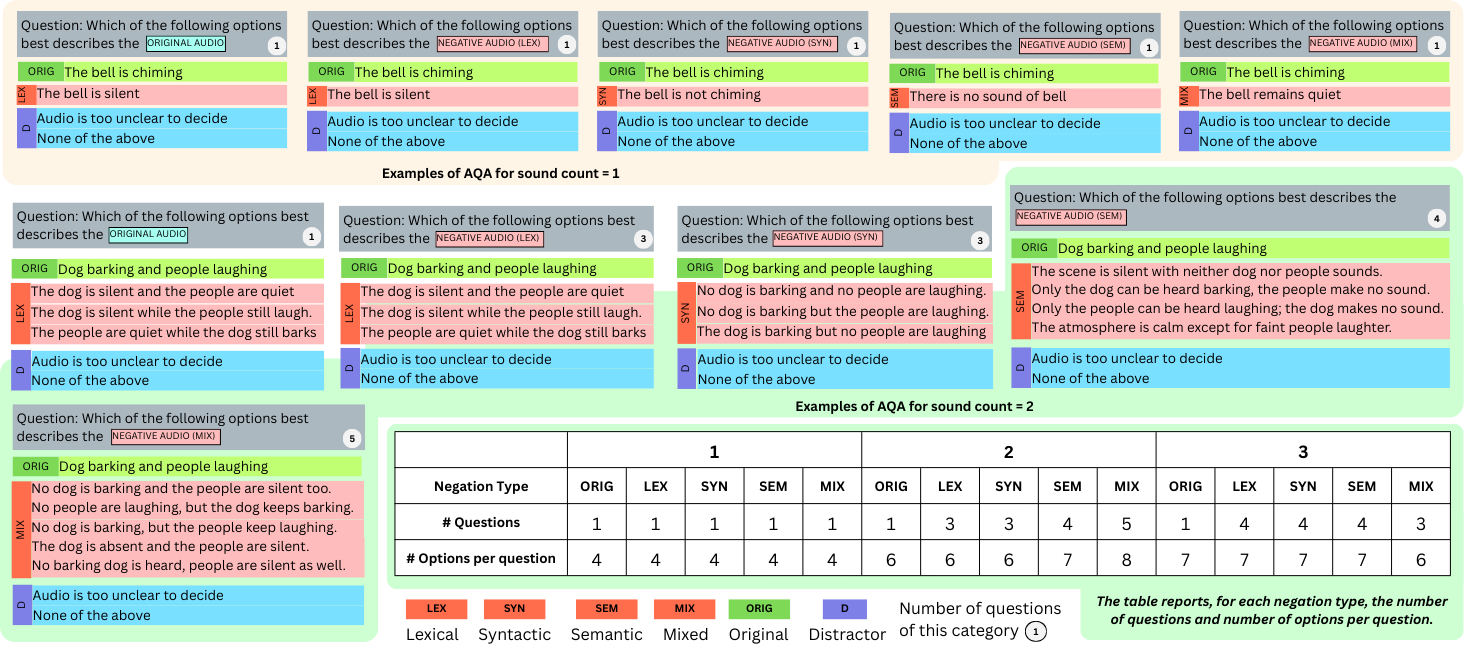
NEGATIVE AUDIO (LEX / SYN / SEM / MIX), the option set is dynamically restricted to the same negation type, the original, and two distractors. The table on the bottom-right reports the number of questions and options per question for each combination.