Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
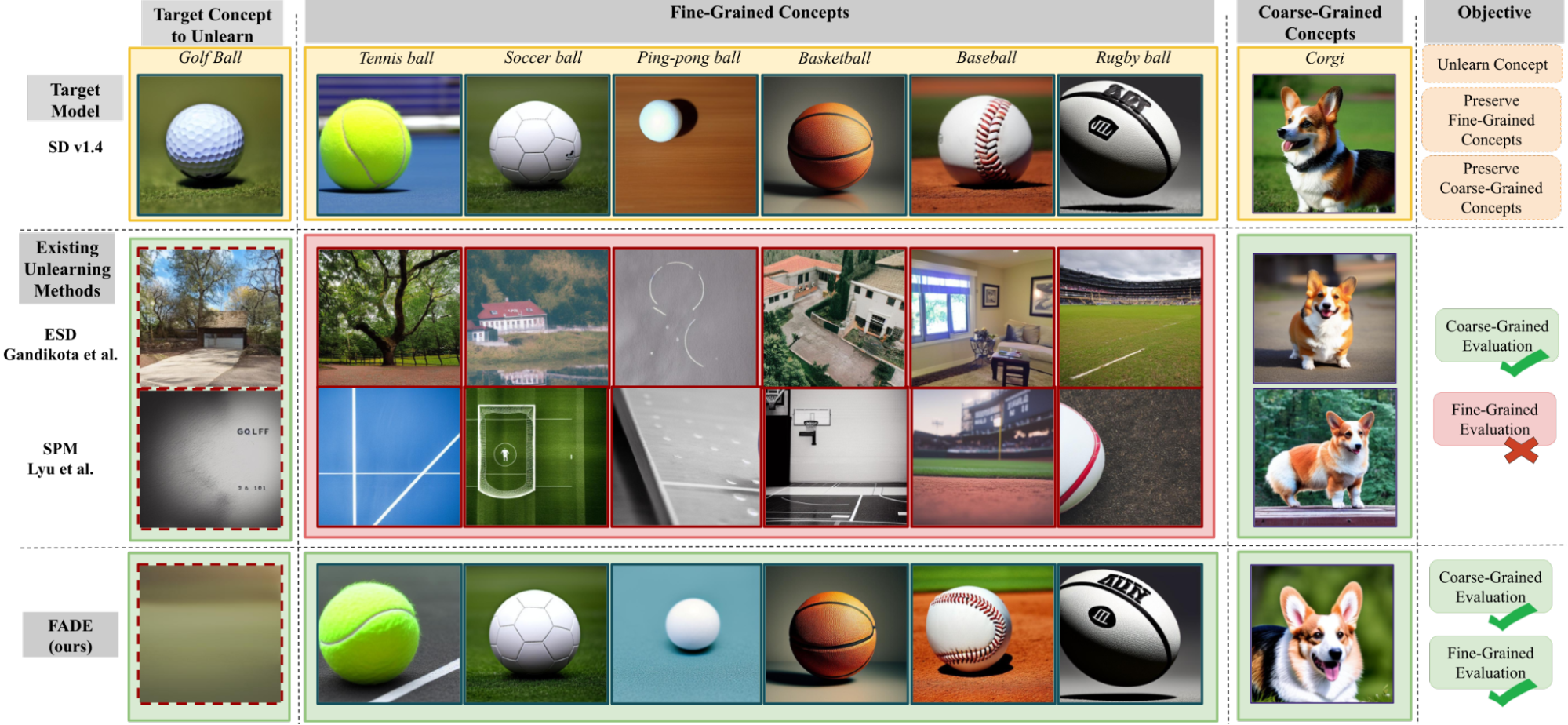
Fine-Grained Concept Erasure: This figure demonstrates the issue of collateral forgetting (termed as adjacency) in selective concept erasure using existing state-of-the-art algorithms in text-to-image diffusion-based foundation models. It highlights the inability of methods that can precisely erase target concepts from a model’s knowledge while preserving its ability to generate closely related concepts.
Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
Existing unlearning algorithms in text-to-image generative models often fail to preserve knowledge of semantically related concepts when removing specific target concepts—a challenge known as adjacency. To address this, we propose FADE (Fine-grained Attenuation for Diffusion Erasure), introducing adjacency-aware unlearning in diffusion models. FADE comprises two components: (1) the Concept Lattice, which identifies an adjacency set of related concepts, and (2) Mesh Modules, employing a structured combination of Expungement, Adjacency, and Guidance loss components. These enable precise erasure of target concepts while preserving fidelity across related and unrelated concepts. Evaluated on datasets like Stanford Dogs, Oxford Flowers, CUB, I2P, Imagenette, and ImageNet-1k, FADE effectively removes target concepts with minimal impact on correlated concepts, achieving at least a 12% improvement in retention performance over state-of-the-art methods.
License Agreement + Citation
The code and data for this research can be accessed at link.
For more info, please refer to the following paper:
Kartik Thakral, Tamar Glaser, Tal Hassner, Mayank Vatsa, Richa Singh, "Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models." The Conference on Computer Vision and Pattern Recognition (CVPR) (Accepted)
@inproceedings{DBLP:conf/cvpr/ThakralGHV025, author = {Kartik Thakral and Tamar Glaser and Tal Hassner and Mayank Vatsa and Richa Singh}, title = {Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models}, booktitle = {{IEEE/CVF} Conference on Computer Vision and Pattern Recognition, {CVPR} 2025, Nashville, TN, USA, June 11-15, 2025}, pages = {9121--9130}, publisher = {Computer Vision Foundation / {IEEE}}, year = {2025}, url = {https://openaccess.thecvf.com/content/CVPR2025/html/Thakral\_Fine-Grained\_Erasure\_in\_Text-to-Image\_Diffusion-based\_Foundation\_Models\_CVPR\_2025\_paper.html}, timestamp = {Mon, 14 Jul 2025 16:00:01 +0200}, biburl = {https://dblp.org/rec/conf/cvpr/ThakralGHV025.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }